
[Python] Bugs에서 주간 음악 순위 Data Scraping하기!
이전에 R을 이용해서는 Web Scraping을 해본 적이 몇 번 있지만(1학년 2학기 수업 때였다.),
파이썬을 이용해서는 Web Scraping을 해본 적이 없어서 방식을 파이썬에 맞게 새롭게 공부해야했다.
하지만 어차피 웹 페이지의 HTML 구조를 이용하는 것 동일했기 때문에 파이썬에서 Web Scraping을 할 때 사용하는 모듈과 함수에 대해서만 새롭게 공부했다. (with 책, 구글링) 구글링은 근데 정말 위대해
뭐 엄청나게 대단한 프로젝트를 진행한 건 아니다. 그저 제일 단순하게 정보만 가져온 것이니까. 기초 중에서 기초를 행했다고 볼 수 있다. 그래도 파이썬을 이용해서 처음 Web Scraping을 해봤기 때문에, 포스트로 기록해보려고 한다.
Bugs의 HTML 구조
먼저, Web Scraping을 위해서는 가장 먼저 내가 이용하려는 웹 사이트의 HTML 소스 코드를 분석해야한다.
내가 이용하려는 웹 사이트는 음악 스트리밍 사이트 중 하나인 ‘벅스(Bugs)’의 주간 차트이다.
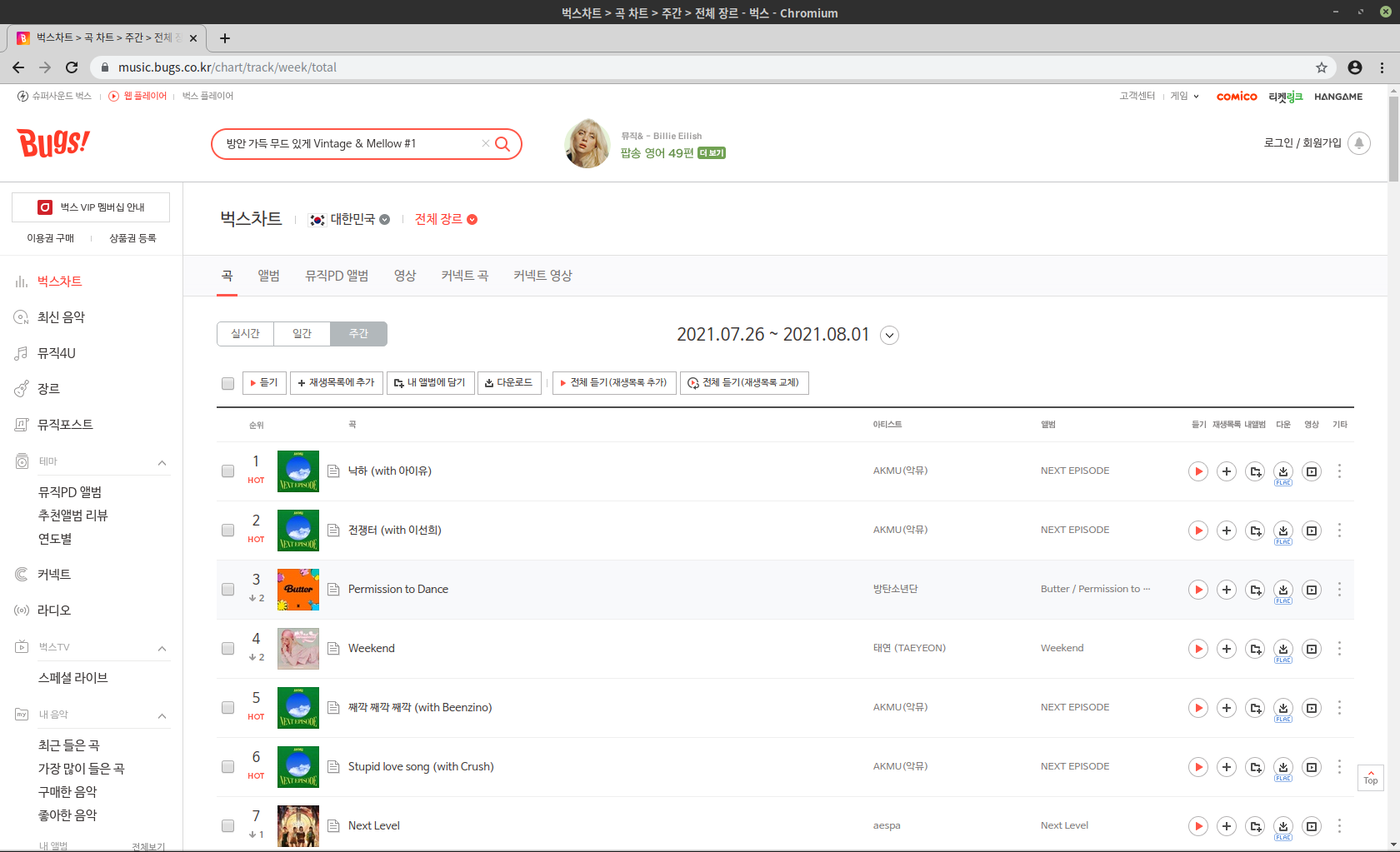
벅스의 주간 차트 사이트에서는 위 이미지에서 볼 수 있듯이 순위, 곡 제목, 아티스트 이름, 앨범명 등의 정보가 나와있다. 필자는 여기서 가장 간단하게 곡 제목과 아티스트 정보만 스크레이핑할 예정이다.
가장 먼저 위 사이트의 HTML 코드를 가져오고, 거기서 곡 제목과 아티스트 이름이 저장되어 있는 태그 요소를 이용할 것이다. 따라서 요소 검사를 통해 살펴보면,
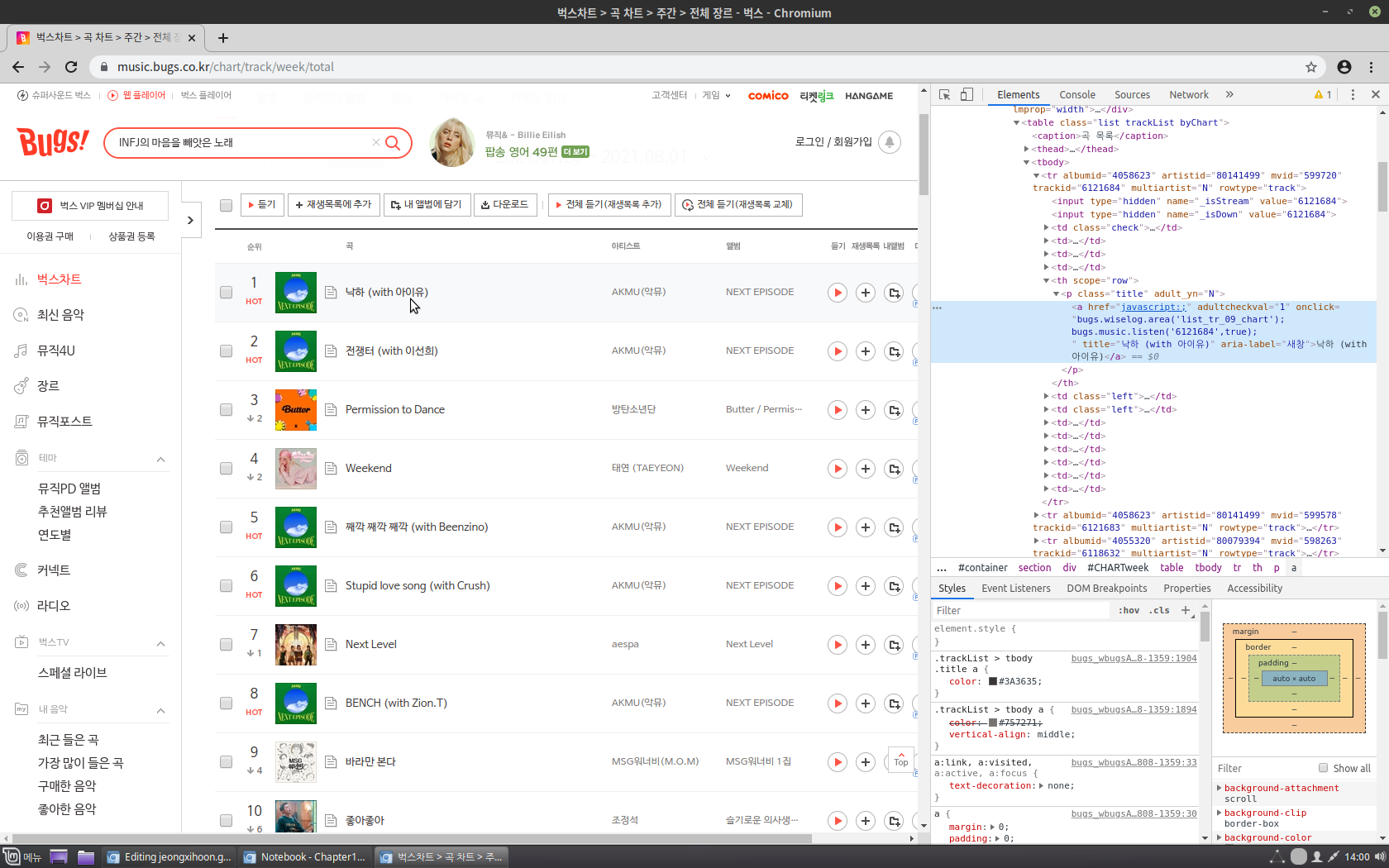
곡 제목은 태그 a에 텍스트 형식으로 존재하고 있는 것을 볼 수 있다. 그렇다고 태그 a로만 소스를 가져오면 다른 태그 a에 존재하는 불필요한 정보들도 가져올 수 있기 때문에 바로 윗 태그인 태그 p에서 class의 속성값이 ‘title’인 요소도 지정하도록 한다. 따라서 select()의 인자에 ‘p.title a’를 입력하도록 한다.
아티스트 이름 또한 동일한 방식으로 확인한 뒤 코드를 다음과 같이 작성하였다.
import requests
from bs4 import BeautifulSoup
url = "https://music.bugs.co.kr/chart/track/week/total"
html_music = requests.get(url).text
soup_music = BeautifulSoup(html_music, 'lxml')
titles = soup_music.select("p.title a")
music_titles = [music_title.get_text() for music_title in titles]
artists = soup_music.select("p.artist a")
music_artists = [music_artist.get_text() for music_artist in artists]
이후 결과를 확인해보니, music_artists에서 원하는 결과가 나오지 않았다.
그 이유는 아티스트 이름의 경우, 웹 페이지에 아티스트가 여러 명인 경우, 추가적인 탭으로 표시하도록 되어있어서 이 경우 아티스트의 이름이 중복해서 Scraping이 되었던 것이다. 그 결과 노래 제목은 100개가 제대로 추출되었지만, 웹 아티스트는 110개가 추출되었다.
그러나 다행인 점은, 중복되어서 추출된 아티스트 이름 정보가 ‘\r’ 등의 불필요한 텍스트도 같이 추출되었다는 점이다. 따라서 데이터 전처리 과정을 거치면 될 것 같다는 생각을 하고 코드를 추가적으로 짰다. 그 코드는 다음과 같다.
#muisc_artists에서 중복되는 가수 제거하기 위한 데이터 전처리 과정
k = 0
for artist in music_artists:
if ("\r" in artist):
del music_artists[k]
k = k + 1
print("<순위> : <곡명> / <가수>")
for i in range(len(music_titles)):
print("{0} : {1} / {2}".format(i + 1, music_titles[i], music_artists[i]))
for문을 통해서 music_artists 리스트의 모든 요소를 검사하면서 만약에 어떠한 요소에 ‘\r’이라는 텍스트가 존재한다면 리스트에서 그 요소 자체를 지워버리는 것이다.
해당 코드를 실행해보았더니 정상적으로 100개의 아티스트 이름만 리스트에 남게 되었다.
따라서 이제 제대로 곡명과 가수가 매치되었는지 확인하기 위해서 print()함수와 for문을 통해서 1위부터 100위까지 순위, 곡명, 가수 순으로 출력되도록 추가적인 코드를 작성했다.
Data 저장하기
이제 데이터를 정상적으로 추출했으니, 이 정보들을 저장하는 코드를 작성했다. 저장 방식은 txt 파일과 xlsx 파일, 이렇게 두 가지 방식을 이용하였다.
첫 번째로는 txt 파일로 저장하는 코드이다.
#txt 파일로 저장하기
file_name = "BugsMusicTop100.txt"
f = open(file_name, 'w', encoding = 'utf-8')
for j in range(len(music_titles)):
f.write("{0} : {1} / {2}\n".format(j + 1, music_titles[j], music_artists[j]))
print("\n", file_name, "저장 완료!")
f.close()
두 번째로는 pandas 모듈을 이용해 추출한 데이터들을 DataFrame으로 저장한 뒤에, 이를 그대로 xlsx 파일(엑셀 파일)로 저장하는 코드이다.
#Pandas - DataFrame과 xlsx 파일로 저장하기
music_titles_artists = {}
rank = 0
for (music_title, music_artist) in zip(music_titles, music_artists):
rank += 1
music_titles_artists[rank] = [music_title, music_artist]
import pandas as pd
df = pd.DataFrame(music_titles_artists).T
df.columns = ['Title', 'Artist']
excel_writer = pd.ExcelWriter('BugsMusicTop100_ExcelFile.xlsx', engine = 'xlsxwriter')
df.to_excel(excel_writer, index = True, index_label = 'Ranking', encoding = 'utf-8')
excel_writer.save()
이 과정을 통해 추출한 데이터들을 txt 파일과 xlsx 파일, 2가지 형태로 저장하였다. 저장 결과는 다음과 같다.
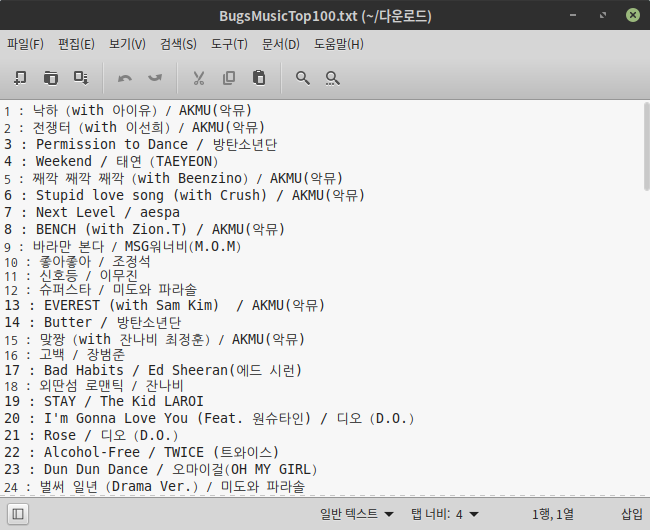
txt 파일로 저장된 결과
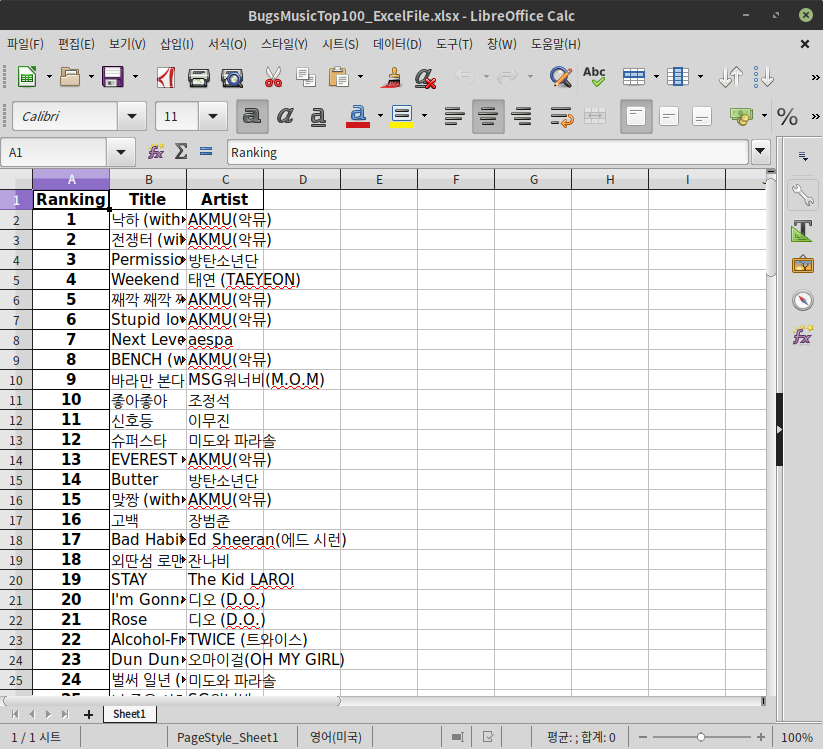
xlsx 파일로 저장된 결과
마무리
코드블럭을 실행한 결과가 포스트에 같이 코드블럭으로 나오면 좋을 것 같은데, 방법을 못 찾아서 일단 그냥 패스했다. 포스트를 더 잘 쓸 수 있을 것 같은데, 스크린샷을 찍고, 일일이 설명하고 그런 과정이 솔직히 좀 귀찮긴 함…ㅎㅎㅎ
원래 포스트 계획은 BeautifulSoup 라이브러리랑 requests 모듈도 간단하게 소개해보려 했는데 이러면 진짜 길어질 것 같아서.그냥 귀찮다고 하자.
예전에 R프로그래밍 과제 할 때는 코드 한 줄, 한 줄 주석을 달아가면서 일일이 다 설명했던 것 같은데 :)… 노력은 가상했다 정지훈…
아무튼 그렇고… 다음 포스트는 아마 ‘웹 페이지에서 이미지 다운로드 하기’가 될 것 같다. 어제 이미 코드는 다 작성하고 실행까지 제대로 된 걸 확인했다. 조만간 포스트를 올리지 않을까…?
그럼 이만, 이번 포스트는 여기서 끝!
P.S.
책으로 Web Scraping 챕터는 끝났다. 이제 다음 챕터는 웹 API이다. 여기는 아예 해본 적이 없는 부분이라서 꼼꼼하게 공부를 해봐야겠다. 챕터 분량도 많은 것 같고, 얼핏 스윽 봤는데 내용이나 활용하는 부분이 꽤 흥미로운 듯.
댓글남기기