
[Python] Reshot에서 무료 이미지 파일 다운로드 하기!
이번에는 웹 페이지에서 이미지를 다운로드 해보기!
웹 사이트에서 우리가 보는 이미지들은 웹 서버 어딘가에 존재하는 이미지 파일이다. 따라서 이미지 주소가 존재하며, 이 주소를 이용하여 이미지를 그대로 다운로드 할 수 있는 것이다!
역시 requests 라이브러리를 이용하였다. (사실 책에서 requests 라이브러리로 다운로드하는 방법밖에 안알려줬음.)
책에서는 먼저 1개의 이미지만 가져오는 코드를 알려주고, 그 다음 여러 개의 이미지를 가져오는 코드를 설명하지만, 본인은 그냥 여러 개의 이미지를 가져오는 코드에 대해서만 간단히 포스팅하려고 한다. 왜냐하면 어차피 유사한 코드를 for문으로 돌려서 반복하는 것이기 때문!
Reshot을 살펴보자!
‘Reshot’ 이라는 사이트는 무료 아이콘, 일러스트, 사진을 무료로 다운로드 받고, 이용할 수 있는 사이트이다. 나중에 PPT 만들 때 아주 유용하게 쓸 듯!
내가 보고 있는 책은 하나하나 스크린 샷을 보여주며 사이트 소개도 해주고 하지만, 나는 귀찮다! 독자께서 위의 하이퍼링크를 통해 들어가서 웹 페이지가 어떻게 되어있는지 보는 것이 좋을 듯하다!
하지만, 그래도 스크린 샷을 올리는 게 맞겠지…?
위는 Reshot 홈페이지에 처음 들어가면 나오는 모습이다.
저 검색창에 키워드를 쓰고 검색을 하게 되면,

이렇게, 해당 키워드를 가진 사진들이 나오게 된다.
Reshot의 사이트 구조는 대강 이렇다. 그렇다면 이제 본격적으로 이미지 다운로드를 위해 필요한 사이트의 HTML 요소들을 살펴보자.
Reshot 사이트와 이미지의 HTML 구조
그렇다면, 이 Reshot 사이트와 키워드를 통해 검색된 사진들의 HTML 구조를 알아보기 위해 검사를 해보자.
본인은 그냥 임의로 ‘car’를 검색하였다.
이건 TMI이긴 한데,
본인은 차와 운전을 좋아하기 때문에 보통 이런거 검색할 때 아무 생각없이 자동차를 검색하는 편… 자동차나 자동차 회사 이름? 그래서 군대에서 지금 운전병을 하고 있지 않은가. 사실 ‘car’를 검색하기 전에, ‘hyundai’, ‘kia’, ‘volvo’를 검색해봤는데 이미지가 2개, 1개 막 이래서 그냥 포괄적으로 ‘car’를 검색한거다!
아무튼!
검색창에 ‘car’를 검색했을 때 가장 처음 보이는 사진에 마우스를 대고 마우스 우클릭을 한 뒤, 검사를 해보았다.
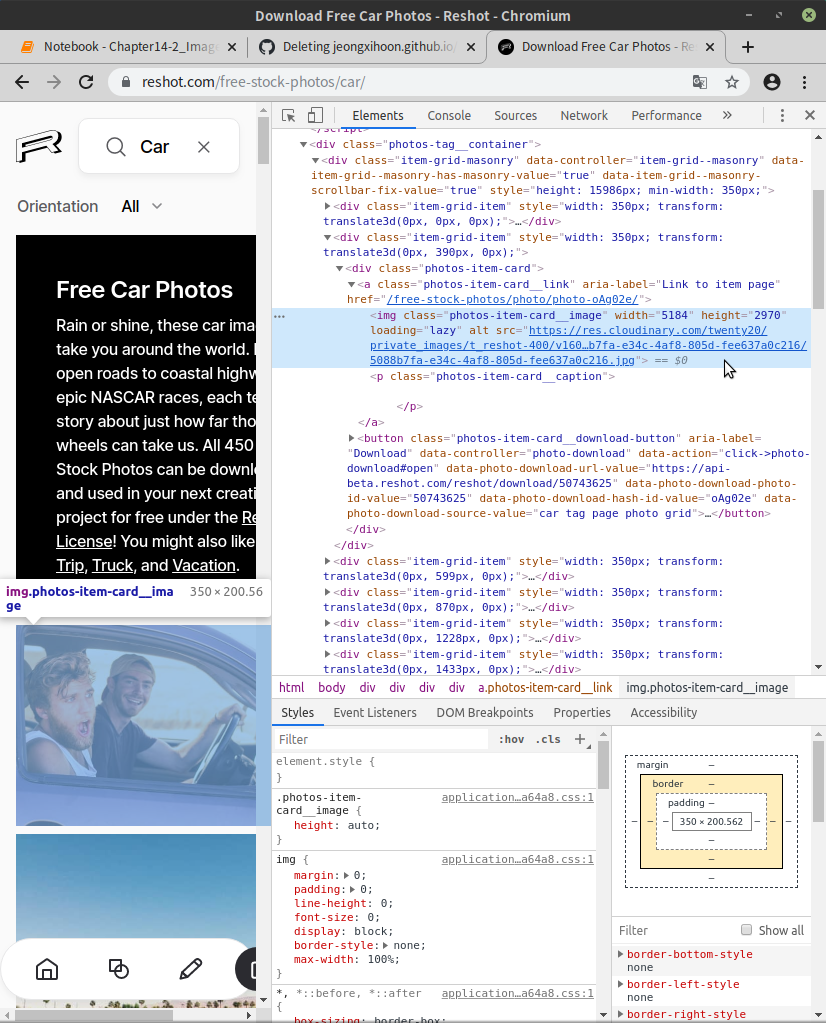
사진에 마우스 포인터 있는 곳을 보면, 이미지의 주소가 보인다! 이제 저 주소를 이용해 이미지를 다운로드 받을 것이다.
이미지 다운로드 하기!
이미지 주소를 이용하여 이미지를 다운로드 받는 메커니즘을 대충 소개하자면 다음과 같다.
requests.get(url)을 이용해 이미지 응답 객체를 가져온다.open(파일 이름, 모드)을 이용해 이미지 파일 저장 준비를 한다.iter_content(chunk_size)를 이용해 이미지 파일을 내려받는다.close()를 이용해open()으로 시작했던 이미지 파일 저장을 마무리한다.
내가 보고 있는 책에서도 예제를 알려주고 있지만, 내 나름대로 출력되는 결과물들이 좀 깔끔하게 정돈되고, 좀 있어보이게 나왔으면 해서 코드를 조금 응용해보았다.
import requests
from bs4 import BeautifulSoup
import os
일단 코드 구현을 위한 module을 모두 불러왔다.
그 다음 본격적으로 코드를 설명해보자면!
1. Reshot 페이지 URL에서 이미지 URL 추출하는 것 까지를 하나의 함수로 구현
def prepareURL():
base_URL = 'https://www.reshot.com/free-stock-photos/car/?page='
# Reshot 페이지 구조가 여러 페이지에 나눠서 사진을 보여주는 구조였다.
page_num = input("이미지 다운로드를 원하는 페이지 번호를 입력하세요. >> ")
# 그래서 사용자가 이미지 다운로드를 원하는 페이지를 직접 입력할 수 있도록 했고,
URL = str(base_URL + page_num)
# 이를 base가 되는 URL과 합쳐서 최종적으로 코드가 이미지를 다운받을 URL을 변수에 저장했다.
html_image_url = requests.get(URL).text
soup_image_url = BeautifulSoup(html_image_url, 'lxml')
image_elements = soup_image_url.select('a img')
# 이미지의 개별 HTML 요소를 가져오기 위해 해당 정보가 저장된 a태그 아래의 img 태그를 select()의 인자로 지정했다.
image_elements = image_elements[1:]
# 각각 이미지의 HTML 요소가 리스트 형태로 저장되어있는데, [0]번째는 홈페이지 로고라서 제거했다.
image_urls = []
for image_element in image_elements:
image_urls.append(image_element.get('src'))
# 각각 이미지의 HTML 요소 중 'src' 속성에 이미지 주소 정보가 저장되어 있다.
# 따라서 for문을 통해서 각각 이미지의 HTML 요소의 'src' 속성에서 이미지 주소 정보를 가져와서 'image_urls' 라는 새로운 리스트에 저장했다.
근데 이거 너무 과제하는 느낌으로 열심히 주석을 달면서 설명하는 것 같은데…?
학점 잘 주실건가요…?
헛소리 치우고,
2. 내려받길 원하는 사진 개수를 직접 지정하도록 함수로 구현
def ImageDownload(image_urls):
image_num = int(input("다운로드를 원하는 이미지 개수를 입력하세요. >> "))
# 말 그대로 다운로드를 원하는 이미지 개수를 입력받아서 변수에 저장한다.
for image_url in image_urls[0:image_num]:
# 그러면, 첫 번째 사진부터 원하는 이미지 개수만큼 for문을 반복하면서 이미지를 다운로드 하게 된다.
html_image = requests.get(image_url)
# 이미지 객체 불러와서,
save_name = os.path.basename(image_url)
# 스스로 함수를 통해 기존에 HTML 파일에 저장된 이미지 파일명을 불러와서
# 동일한 이름으로 이미지 다운로드 파일명을 저장한다.
imageFile = open(os.path.join('download', save_name), 'wb')
# 내가 실행시키는 환경을 기준으로 'download'라는 폴더에 이미지 다운로드 파일명을 붙여서 경로를 지정한다.
# 그리고 '쓰기모드(b)'와 '바이너리 파일모드(b)'를 지정해준다.
# 텍스트 파일이 아니라 이미지 파일이기 때문에 바이너리 파일모드(b)로 지정을 해야한다.
chunk_size = 1000000
# 1000000byte씩 나눠서 다운로드할 예정이다.
for chunk in html_image.iter_content(chunk_size):
imageFile.write(chunk)
# for문과 iter_content()함수를 통해 각각의 이미지를 1000000byte씩 나눠서 내려받고
imageFile.close()
# 완전히 1개의 이미지 다운로드가 끝나면 close()함수로 이미지를 저장한다.
print('- 이미지 파일 이름: "{0}" >> 저장 완료!'.format(save_name))
print("-----------------------------------------------------------------")
print("{0}개의 이미지 파일, 정상적으로 저장 완료!".format(image_num))
# 최종적으로 원하는 개수 만큼의 이미지 다운로드가 완료되면 해당 print()문을 실행하고 코드가 종료된다.
이렇게 함수를 짜고
이를 이용하여 실질적으로 이미지를 다운로드 받고 싶으면 메인코드에 다음과 같이 실행하면 된다.
# 이건 그냥 메인에서의 실행코드이다.
# 최종적으로 이렇게 2개의 함수만 실행하면 원하는 페이지에서 원하는 개수의 이미지를 다운로드할 수 있다!
if __name__ == '__main__':
prepareURL()
ImageDownload(image_urls)
마무리
이렇게 복잡한 듯, 복잡하지 않은 ‘이미지 다운로드 코드’에 대한 설명이 끝났다.
또 갑자기 급하게 마무리되는 듯한 느낌이 드는군.
하지만 더 이상 설명할 것이 없긴 하다.
Web Scraping 챕터는 이제 끝났다. 다음은 ‘웹 API’에 대한 내용이다.
지금 사실 이 포스트를 쓰고 있는 건 아까 22시 30분쯤 내가 사용할 웹 API 데이터의 활용 신청을 해서 API Key를 받았는데, 이게 API Key를 받고 1~2시간 이후부터 접속 권한이 주어진다는 것이다…!
그래서 연등 시간 안에는 사용할 수가 없어서 뭘 할까 생각하다가 이번 포스팅을 쓰게 되었다.
어차피 이번 주말에 할 일을 미리 한거니까 뭐! 좋아좋아.
내일은 오늘 못한 웹 API를 해보도록 하자.
이번 포스트는 여기서 끝!
댓글남기기